

First start let’s start with a definition. In this context – dynamic memory means acquiring and releasing memory at run time vs. statically allocating memory at compile time.
Depending on your upbringing and experience the use of dynamic memory is axiomatic. Especially when dealing with interpreted languages (e.g. python) or languages that natively support garbage collection (e.g. JAVA, C#) that shields and protects the programming from all of the gory details and responsibilities with allocating and freeing memory. That said most embedded systems (think MCU based projects) use C/C++. These languages do not natively support garbage collection and rely on the programmer to explicitly allocate and free dynamic memory. Yes, C++ has ‘smart pointers’ that help to manage/prevent memory leaks, but the smart pointers do nothing to prevent heap fragmentation.
So why is dynamic memory “a bad thing”. The short answer is: because requests for a chunk of memory at run time can fail.
The slightly longer answer is: because memory requests can fail, it greatly complicates your code in dealing with all of the possible error paths and what-to-do logic when memory can’t be allocated. When your target platform has mega or giga bytes of RAM memory, the probability of the runtime memory allocation failures are greatly reduced and as such, becomes a lesser concern. However on a Microcontroller target, RAM memory is measured kilo bytes (or less) and the possibility of runtime memory allocation failures are a first class issue and needs to be addressed as part of the software architecture and design.
Types of dynamic memory
There are two types of dynamic memory in a program:
- Stack
- Heap
Stack
Each thread in your program has a stack. The stack grows in size as local function variables are pushed on to the stack and when calling a function (i.e. pushing function arguments and saving the caller’s register context). The stack shrinks when returning from function calls (i.e. popping the function’s stack frame).
The concern with the stack – is when recursion logic is used. Recursion is really just dynamic memory allocation in disguise, i.e. using the stack instead of the heap as the memory source. Recursion is also more dangerous because instead of a failure indication when memory is exhausted – a stack overrun simply overwrites ‘other’ memory. A stack overrun is even more likely on embedded systems since stack sizes on embedded platforms are typically small, e.g. 0.5K to 4K range.
Yes, in some cases, the recursion is bounded, i.e. maximum stack usage can be statically determined. However, I claim that even for these cases it is just delaying the failure because when the code is maintained and extended over time – the stack math gets invalidated, and probability of the stack math being recalculated and verified is low – especially when the refactoring is done by a different developer.
Heap
The heap is what most developers think about when it comes to allocating memory at run time. For C/C++ when explicitly requesting from memory from heap – the call will either fail (i.e. return a null pointer) or in C++ throw an exception. Having to deal with the failed memory requests can get extremely problematic for embedded systems where it is not acceptable to simply reboot or quit functioning.
What can cause the heap to be out-of-memory?
- The application’s memory needs exceed the heap size.
- The application has a memory leak and fails to return memory to the heap. Over time the leak exhausts all of the heap memory.
- Fragmentation. The heap will become fragmented over time as blocks – of different sizes – are allocated and freed. See the diagram below. Since embedded systems typically are required to run for days, months, years between rebooting (along limit heap sizes) – fragmentation becomes matter of when, not if.
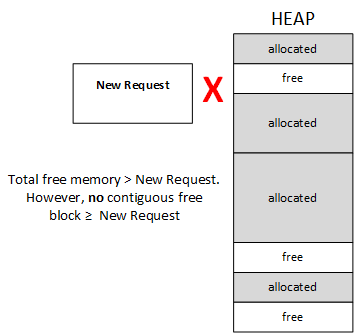
The simplest (not the same as the “easiest”) solution is not to use the heap at all. In fact in some industries this is codified into their best practices, standards, and design methodologies. There are also other partial solutions like using self-managed memory pools to address fragmentation. Memory pools are a topic for future blog article.
I prefer a variant to the no-heap-allowed rule. The heap can be used during the start-up sequence of application but not afterwards. By allowing heap usage during start-up simplifies memory allocation strategies when the application has runtime configuration options that directly or indirectly dictates the amount of memory needed. The benefit of this approach are:
- The application will not crash over time due to lack of memory, i.e. if the application gets past the start-up sequence – all of the needed RAM has been allocated.
- Typically, it is okay to reboot and go into a unrecoverable error state if there is failure during start-up.
- The heap never gets fragmented (because nothing is ever freed)
Summary
- Do not use recursive programming logic
- Do not allocate memory from heap once the program has completed its start-up logic.